The Post-Modern Data Stack is about reducing friction, not adding tools. It’s about building end-to-end data systems that are declarative, open, and composable, without the complexity and lock-in of the Modern Data era.
Starlake and DuckLake embody this philosophy. Starlake unifies ingestion, transformation, and orchestration through declarative YAML, while DuckLake delivers a lightweight, SQL-backed lake format with ACID transactions, schema evolution, and time travel, all on open Parquet files.
Together, they let you start small, develop locally, and scale seamlessly to the cloud, without changing your model or mindset.
The "Modern Data Stack" (MDS) brought cloud agility, but also fragmentation, hidden complexity, vendor lock-in, and brittle pipelines. Performance and openness are equally critical.
For example, in an independent TPC-H SF100 benchmark on Parquet files, DuckDB delivered sub-second query times for most queries. This proves that open file formats plus a high-performance engine can match traditional analytics platforms at a fraction of the cost.
DuckLake: A Lake Format for the Post-Modern Stack
DuckLake introduces a next-generation lake format built on Parquet, coordinated by a real SQL database (PostgreSQL, MySQL, SQLite, or DuckDB). This design unlocks:
Multi-user collaboration: SQL-based catalog enables concurrent reads and writes with transactional guarantees.
ACID transactions & snapshots: Full transactional integrity, snapshot isolation, time travel, and schema evolution, reliability once reserved for data warehouses.
Open & composable: Based on open standards (SQL + Parquet), so you can use your favorite engines and orchestration tools. No proprietary runtimes or hidden metadata.
Local-to-cloud consistency: Develop locally with DuckDB, then deploy to a shared PostgreSQL-backed DuckLake in the cloud, no rewrites, no migrations, no friction.
version:1 application: connectionRef:{{ACTIVE_CONNECTION}} connections: ducklake_local: type: jdbc options: url:"jdbc:duckdb:" driver:"org.duckdb.DuckDBDriver" preActions:> INSTALL ducklake; LOAD ducklake; ATTACH IF NOT EXISTS 'ducklake:/local/path/metadata.ducklake' As my_ducklake (DATA_PATH '/local/path/'); USE my_ducklake;
Set ACTIVE_CONNECTION=ducklake_local for local development.
Scale to the cloud: Change your DuckLake catalog connection to PostgreSQL or MySQL, and update DATA_PATH to your cloud storage (e.g., GCS, S3):
application.sl.yml for cloud deployment
version:1 application: connectionRef:"ducklake_cloud" connections: ducklake_cloud: type: jdbc options: url:"jdbc:postgresql://your_postgres_host/ducklake_catalog" driver:"org.postgresql.Driver" preActions:> INSTALL POSTGRES; INSTALL ducklake; LOAD POSTGRES; LOAD ducklake; CREATE OR REPLACE SECRET ( type gcs, key_id '{{DUCKLAKE_HMAC_ACCESS_KEY_ID}}', secret '{{DUCKLAKE_HMAC_SECRET_ACCESS_KEY}}' SCOPE 'gs://ducklake_bucket/data_files/'); ATTACH IF NOT EXISTS 'ducklake:postgres: dbname=ducklake_catalog host=your_postgres_host port=5432 user=dbuser password={{DUCKLAKE_PASSWORD}}' AS my_ducklake (DATA_PATH 'gs://ducklake_bucket/data_files/');
Set ACTIVE_CONNECTION=ducklake_cloud for cloud deployment. You can now transition from local to cloud without changing your data models or transformation logic.
Metadata enables lineage, versioning, auditing for trusted ingestion
SQL-only, portable transformations
Transformation logic as plain SQL, no templating
Parquet + catalog via SQL keeps transformations portable and engine-agnostic
Local dev, global deployment
DuckDB local dev, deploys with no changes
Supports DuckDB locally, scales to larger catalogs/storage; same data format persists
Git-style data branching
Snapshot/branching semantics for datasets
Snapshots/time-travel provide data versioning like code branches
Orchestration-agnostic pipelines
SQL lineage, DAGs for any orchestrator
Unified metadata for referencing dataset versions, dependencies, and snapshots
Semantic modelling agnostic
Outputs semantic layer models for multiple BI platforms
Open, portable dataset format; semantic models not locked to one tool
Why DuckLake is a Strong Alternative to Cloud Data Warehouses
DuckLake offers a unique set of advantages over cloud-based data warehouse solutions like BigQuery, Snowflake, and Databricks:
Lower and Predictable Costs: DuckLake minimizes costs by allowing you to store data directly in open Parquet files on affordable object storage (like S3, GCS, or on-premises solutions), without requiring expensive proprietary compute or storage layers. You avoid per-query or per-user fees, and only pay for the storage and compute you actually use, making budgeting straightforward and cost-efficient.
Full Data Control and Privacy: With DuckLake, your data never leaves your environment. This makes it easier to comply with privacy regulations and internal security policies, and lets you implement custom security measures as needed.
Optimized Performance: DuckLake achieves high performance by leveraging the efficiency of the Parquet file format and the power of embedded analytical engines like DuckDB. By operating directly on columnar storage and minimizing data movement, DuckLake delivers fast query execution and analytics, even on large datasets, without the overhead of traditional data warehouses.
Open and Transparent: The open source codebase means you can audit, modify, and extend DuckLake as you see fit. There are no hidden operations or proprietary formats.
Vibrant Community and Ecosystem: DuckLake benefits from an active open source community that continuously improves the platform, provides support, and shares best practices. Its foundation on open standards ensures compatibility with a wide range of tools and platforms, making data migration and integration straightforward as your requirements change.
While solutions like DuckLake offer many advantages, cloud data warehouses such as BigQuery, Snowflake, and Databricks also provide significant added value:
Fully Managed Service: Cloud data warehouses handle infrastructure, scaling, maintenance, and updates automatically, reducing operational overhead for your team.
Elastic Scalability: Instantly scale compute and storage resources up or down to match workload demands, paying only for what you use.
Integrated Ecosystem: Seamless integration with a wide range of cloud-native tools for analytics, machine learning, data ingestion, and visualization.
High Availability & Disaster Recovery: Built-in redundancy, backup, and failover capabilities ensure data durability and business continuity.
Global Accessibility: Access your data securely from anywhere in the world, supporting distributed teams and global operations.
Advanced Security & Compliance: Enterprise-grade security features, compliance certifications, and fine-grained access controls are managed by the provider.
Performance Optimization: Providers continuously optimize performance behind the scenes, leveraging the latest hardware and software advancements.
These features make cloud data warehouses an attractive choice for organizations seeking minimal operational burden, rapid scaling, and access to a rich ecosystem of managed services.
Starlake and DuckLake represent a decisive shift toward the Post-Modern Data Stack, where openness, simplicity, and scalability coexist. Instead of assembling a tangle of incompatible tools, data teams can now build pipelines that are declarative, SQL-driven, and environment-agnostic from day one.
With Starlake, you define your data flow once: ingestion, transformation, validation, orchestration, all in YAML and SQL. With DuckLake, you store and query your data in an open, transactional lake format that scales from a local DuckDB setup to a cloud-backed PostgreSQL catalog. The result: a development experience as simple as working on your laptop, yet scalable to enterprise-grade reliability and performance.
Recent performance tests show DuckLake processing 600 million TPC-H records in under 1 second for most queries, proving you don’t need heavyweight infrastructure for warehouse-class performance.
The future of data engineering is declarative, composable, and open. With Starlake + DuckLake, you can truly start small and scale big, without ever compromising on speed, quality, or control.
The "Modern Data Stack" (MDS) gave us cloud agility, but it also delivered complexity: fragmented tools, opaque lineage, and dialect lock-in. It's time to move past the modern toward the declarative.
The Declarative Data Stack isn't just another layer on the MDS; it’s a foundational rethinking of data engineering, offering a simpler, faster, and more secure pathway to production-grade data.
Starlake is distinguished by its declarative, configuration-as-code approach: all of its features and settings, from ingestion to semantic modeling are defined using the simple, unified YAML declarative language. This allows data pipelines to be treated as robust, version-controlled software artifacts.
1. Quality-First Ingestion: Moving Beyond Simple Data Movement
Traditional data stacks focus heavily on ETL/ELT—moving data from Point A to Point B. But what good is fast movement if the data is garbage? Starlake starts with quality.
Validation is Core: Starlake is not just about data movement; it thoroughly validates the incoming data against your defined schemas and business rules before it enters your transformation pipeline.
Built-in Data Quality: Instead of requiring a separate, bolted-on data quality tool, Starlake integrates validation, cleansing, and quality checks into the very first layer of ingestion.
The Benefit: By validating data at the source, Starlake ensures only high-quality, trusted data flows into your warehouse, reducing errors downstream and eliminating the "garbage in, garbage out" problem.
The MDS insists on embedding logic (like Jinja or proprietary domain-specific languages) directly into your SQL. This adds complexity and breaks portability.
Modern Data Stack Way
Starlake Declarative Way
Uses Jinja to manage table relationships and lineage.
Uses SQL only. No complex templating language required.
SQL cannot be easily copy-pasted or run outside the tool.
SQL is pure and portable. Copy/paste your transformation logic from any tool (like DBeaver or Snowsight) and it just works.
The Benefit: By isolating transformation logic to pure SQL, Starlake automatically derives table and column lineage, making your pipelines transparent, auditable, and accessible to any SQL developer, regardless of their background or tool they use.
Why should developing a data pipeline require a costly, minutes-long compile-and-test cycle on your production data warehouse? With Starlake, you don't have to.
Starlake embraces a local-first philosophy thanks to transparent transpilation:
Develop Locally, Deploy Globally: Develop and debug your entire pipeline using DuckDB on your laptop. DuckDB offers lightning-fast, zero-cost execution on your sample data.
Transparent Transpilation: Starlake automatically converts your written datawarehouse’s SQL dialect (Snowflake, BigQuery, Spark ...) into the DuckDB dialect when running locally. When you deploy, the original datawarehouse’s SQL is used.
Faster CI/CD: You can run full Continuous Integration tests on your SQL transformations without ever hitting your data warehouse, dramatically reducing CI/CD costs and iteration time.
The Benefit: Achieve faster development cycles and reduced costs by decoupling the development environment from the costly production warehouse.
Branching code is standard. Branching data is often a nightmare of expensive copies and complex synchronization. Starlake solves this using the datawarehouse’s powerful SNAPSHOT feature.
Zero Copy Data Branching: Starlake creates a logical "branch" of your production data. This is not a costly physical copy. Instead, it’s a zero copy operation—a pointer to the production data at a moment in time.
Production Data Safety: Users get read-only rights on the production data, allowing safe exploration, testing, and development without any risk of accidentally updating or corrupting the live environment.
The Benefit: Enable agile data development and experimentation by allowing teams to work on production data safely and efficiently, just as developers work on code branches in Git.
5. Orchestration Agnostic: Your Orchestrator, Our Lineage
No vendor lock-in. Just clean, native orchestration, powered by lineage.
The MDS often requires you to use a specific tool (or a proprietary orchestrator) just to manage pipeline dependencies. Starlake believes orchestration should be a pluggable utility.
Automatic Execution Graph: Through its analysis of the pure SQL lineage, Starlake automatically generates the execution dependencies (the DAG).
Orchestration Agnostic Deployment: Instead of wiring dependencies manually, Starlake generates from SQL lineage, event-driven and dataset-aware DAGs for your orchestrator of choice (e.g., Snowflake Tasks, Google Cloud Composer, Airflow, Dagster, etc.).
The Benefit: You leverage the native orchestration capabilities of your data cloud, leading to simplified infrastructure and reduced dependency management.
Semantic models should serve your business logic, not be locked to a single BI tool. Starlake breaks down the silos between the business users and the dataviz developers.
Business logic shouldn’t live and die inside multiple dashboards. With Starlake, your metrics and relationships are declared once at the business level and then automatically available in multiple semantic formats:
Snowflake Cortex Analyst semantic model
Power BI TMDL
Looker LookML
That means your KPIs are consistent across dashboards - no more "metric drift" between tools.
The Benefit: Ensure consistency across your BI landscape and avoid expensive, error-prone manual translations of business metrics between tools.
7. CLI and GUI Support: Code When You Want, Click When You Don't
The Declarative Data Stack recognizes that different users have different needs.
CLI (Code): Data Engineers and developers can use the Command Line Interface for scripting, automation, and complex pipeline management.
GUI (Click): Data Analysts and less technical users can use the Graphical User Interface to configure simple ingestion, view lineage, and monitor health.
The Benefit:Unify your data team by providing tools optimized for both code-first engineers and visual analysts, maximizing efficiency for everyone.
Most data teams spend 80% of their time wrestling with infrastructure—writing custom UPSERT logic, building incremental loading from scratch, or debugging why their Airflow DAGs failed again at 2 AM. Meanwhile, the business is still waiting for those critical data insights.
This article is a follow-up to Part 1, where we explored declarative data stacks. Here, we dive into the specific capabilities that let you skip most of the engineering challenges and focus on delivering business value. You'll discover how to extract and load data from multiple sources with built-in quality controls, configure complex write strategies like SCD2 and UPSERT with simple configuration changes, and transform data using SQL that transpiles seamlessly across BigQuery, Snowflake, Databricks, and DuckDB. We'll also explore how to generate production-ready orchestration workflows without writing custom code, all while testing locally before deploying to production.
By the end, you'll see how declarative approaches can eliminate custom development while giving you enterprise features that usually require dedicated platform teams, from automated data quality validation to intelligent dependency management across multiple execution engines.
In Part 3, we'll explore advanced use cases and unique features that make Starlake particularly powerful for complex data scenarios.
Why Declarative Data Stacks Go Beyond the Modern Data Stack
Let's quickly recap why you'd want a declarative data stack. The modern data stack is only a definition and not something that exists physically. But generally, it's defined as a modular stack where you can flexibly exchange certain data tools and combine them, leading to integration into an end-to-end data platform.
This is also where most of the frustration comes from—some of them do not work well together, and it's a lot of work with constant changes on each of the tools while you try to build. Though the code and license to use the tools cost nothing, it's expensive to set up yourself if you don't have the expertise.
This is where a declarative stack comes in handy. It's a pre-built framework to stitch together the best-in-class tools. It's opinionated toward tools that work well together, but that comes with a big efficiency gain. Plus, you can get started in minutes, as everything is declarative.
Starlake, for example, allows you to configure your stack with only configurations. It's as if it came from one vendor or platform, and you have a unified configuration layer to set up and configure your data stack despite using various tools from the data stack behind the scenes.
The Configuration-First Approach to Data Platform Building
A declarative data stack lets you focus on the business challenges and use automation with orchestration and other complex topics that are usually added as an afterthought from day one. Because Starlake is open-source and uses the so-called Modern Data Stack, there's no vendor lock-in.
Starlake uses external engines to run its compute. With SQL transpilers and support for multiple engines, you can easily switch your compute while having the same business logic and integration from Starlake. Plus, you get instant scaling through having external engines.
Where declarative data stacks shine is when complexity grows. With a predefined setup that's built and used in some of the biggest companies in France and elsewhere, you are prepared for that growth. Starlake was built from the ground up to fix this with declarative configurations. Instead of glue code, type-safe definitions, built-in orchestration integration, and full cloud flexibility, all open-source.
If you want to know more about Starlake's open-source declarative data platform and why you might consider it for an enterprise use case, I suggest checking out Part 1 first. Otherwise, let's explore Starlake in action before we focus on the key features that make it very interesting for data engineers later in this article.
In this chapter, we cover capabilities that every data engineer needs for a successful analytics solution: solving the fundamental data engineering jobs and delivering analytics results with capabilities that come out of the box with Starlake, supporting beyond basic ETL.
Illustration of Starlake with its modular structure from extract, load and transform, connected by orchestration.
Powerful features include:
No-Code Data Ingestion: Connect to any data source through simple YAML configurations without writing custom extraction code.
Data Governance and Quality at every step: Built-in validation rules and lineage tracking ensure data reliability from ingestion to analytics.
Automated Workflow Orchestration: Dependencies and scheduling are handled automatically based on your declarative configurations.
In the next chapters, we go through them step by step and elaborate on how a declarative data stack like Starlake works and the capabilities it offers.
Extracting is the direct way to load from your source databases. The extraction lets you extract tables in one shot and incrementally from a database as a set of files.
Load, on the other hand, is when you load from local files or files on S3/R2, for example. This is loading your Parquet, CSV, or JSON files.
Apache Kafka, Amazon Kinesis, Google Pub/Sub, Azure Event Hubs
For some warehouses or cloud providers, deep integration exists. For example, with Snowflake through Snowflake's Native App capability, you simply install: install starlake -> native app and get all the features inside Snowflake. This allows you to avoid sharing your Snowflake credentials with an external SaaS platform and avoid data exfiltration, as well as use your Snowflake compute credits to run Starlake and have a unified bill.
You can use markup on top of Snowflake and avoid DevOps. With Starlake as a native app, it means no security headaches, credentials are never shared, and no data is exfiltrated. Everything is SQL, and the data is secure in Snowflake. You save a lot of time by not needing to do this work.
Organized by Domain
In Starlake, the data is organized by domains. A domain is a database schema also called a dataset on BigQuery.
The loading capabilities go beyond moving files. For example, we can set data types and their format at the beginning when we load, which applies them for everyone at the very beginning of loading. We can set attributes and write strategies
such as APPEND, OVERWRITE, UPSERT_BY_KEY, UPSERT_BY_TIMESTAMP, DELETE_THEN_INSERT, SCD2, or even ADAPTIVE. These are all very powerful on their own, as typically you'd need to write your own extensive custom code, especially for incremental, Slowly Changing Dimension (Type 2), or UPSERTs. Having these integrated and switching quickly by just changing the writing strategy is handy and significant.
Example of how to load data and its configurations in Starlake GUI
Dedup Strategy for Better Data Quality
Write Strategies help you always make sure users won't see duplicated rows where specified. For example, you can specify that a customer data table should be deduped, and Starlake makes sure to upsert the data accordingly.
Type Validations and expectations are two features to improve data quality out of the box. It validates the types of the data you are loading by specifying the schema, and with expectations, allows you to test if the resulting table contains the expected data.
Transform on Load to quickly add columns you need but are not provided by the source database, such as load-time or locally formatted timestamp.
For BigQuery and Databricks, there is a feature that supports their user-defined clustering and partitioning to improve the performance of queries on large datasets.
Access Control with ACL or row-level security for Snowflake, BigQuery or Spark is built in. This is pretty cool.
All of these configurations have one place to configure all your data needs, and they will be propagated downstream to all your consumers.
Other powerful and advanced enterprise features that you'd spend much time and effort to build otherwise are:
No-Code Data Ingestion
Cloud-Native Integration
Security & Governance
Real-time streaming via Kafka
Native AWS, GCP, Azure support
Built-in error handling & recovery
Cloud-agnostic deployment
Column-level encryption
Alerting, Freshness, Schedule
Serverless execution
Data masking & anonymization
Multi-cloud data sync
Audit logging & compliance
GDPR & CCPA support
Beyond core data processing, Starlake excels in development workflow and platform integration:
We can also define foreign keys and primary keys in the load menu. This helps us model the data when we combine different sources and create new tables, or if the data source does not have any proper relations set.
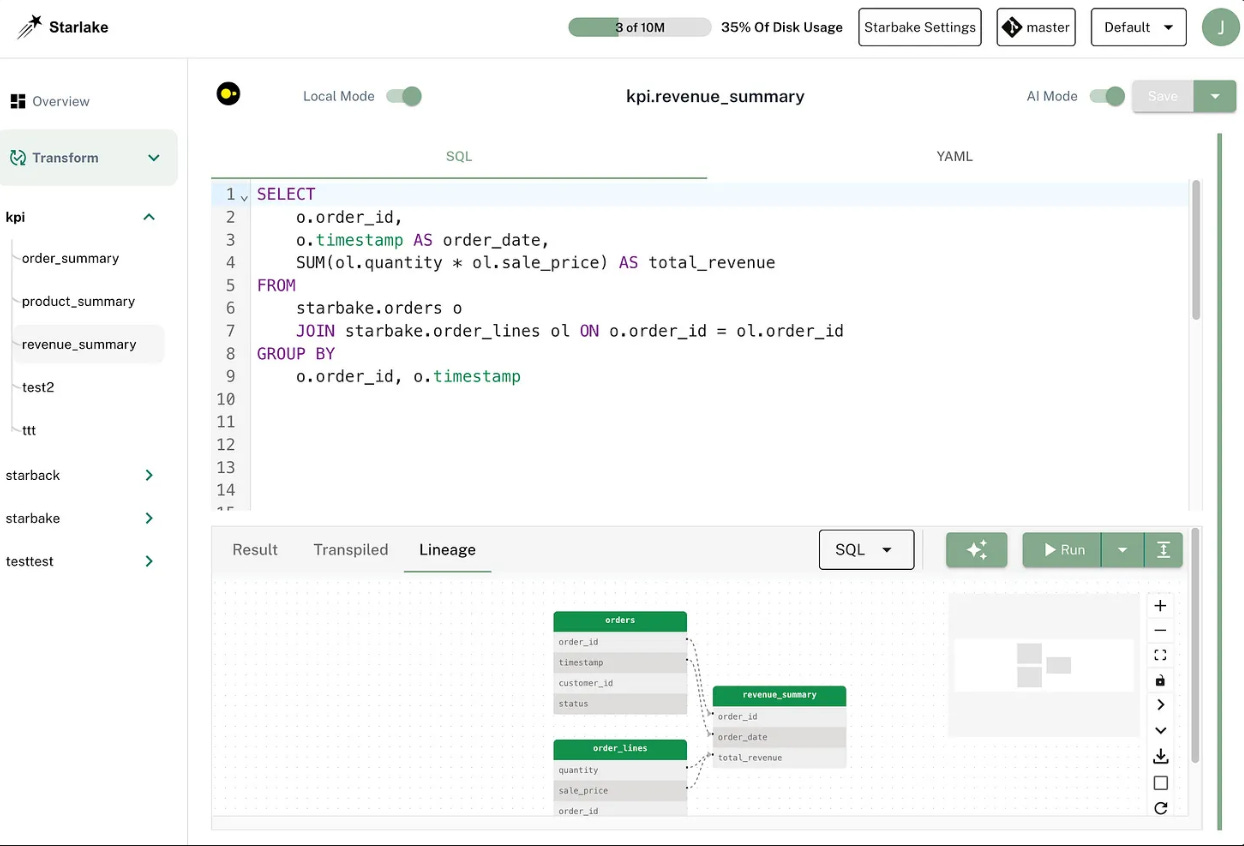
Transforms are the critical business logic. We define them mostly in SQL and Python, and custom transformations are also possible. We can define them in the worksheet.
Starlake worksheet data transformation example.
We can then preview our transformation to check if we have the right granularity or result. But beyond that, we can transpile into other SQL dialects if we want to test our DuckDB SQL on our Spark or BigQuery cluster. This allows us to test the SQL on top of an in-memory DuckDB database without hitting the data warehouse, inducing more interactivity and less cost.
If you click on preview, it will show transpiled code for the current configured engine that's going to be run. Or we can just check the lineage for that aggregation.
Preview our data aggregation—or hit transpiled or lineage to see more detailed information.
These transformations can be stacked upon each other, building your data application with newly created data models and powerful aggregations. Check out a demo here.
An example of column-level lineage with its dependencies and an overview of your data assets in the web UI. Hovering with the mouse will reveal the transformation applied (see SUM() above).
Lineage from plain SQL
Thanks to its deep integration with open-source projects like JSQLParser and JSQLTranspiler (both funded by Starlake),
the platform can automatically infer data lineage directly from your SQL statements.
This enables Starlake to generate orchestrator DAGs and manage dependencies without requiring manual Jinja references
or explicit dependency declarations.
As a result, orchestration order and lineage tracking are handled by the platform, freeing developers from boilerplate and reducing the risk of errors.
This also makes it easy to copy and share queries with other team members, streamlining collaboration and reducing friction in your workflow.
The next step is to test, orchestrate, and deploy. Testing is most important in data engineering and data analytics platforms because if we have false key performance indicators (KPI) or get inconsistent data, business consumers of the data won't trust the data anymore.
That's where extensive tests such as unit tests and full tasks for loading or transformation come in. These tests check the correctness of the data transformations, the data loading process, and the data quality.
Type validation is built-in and done with DuckDB. For example, you can get quite creative to define your types and have them validated ahead of runtime through a test dataset.
When you have rejected rows during a production run, these can be written to specific rejected tables with rows that invalidated the definition, including a report summary. This allows only valid data in the system and provides an elegant way to send a report based on the rejected table to the domain owner with invalid data for further analysis.
The best part is that Starlake allows you to test load tasks locally (using DuckDB) before deploying to production. This helps you save many development cycles as we can avoid running a long-running task at night only to find a typo in the morning.
Orchestration is for scheduling the transformations on a regular schedule using your orchestration tool of choice. For example, Dagster, Airflow, or Snowflake Tasks are integrated.
Starlake doesn't have its own orchestrator but uses major open-source ones. It natively integrates with Dagster or Airflow, or you can use Snowflake Tasks (Snowflake's native orchestrator), to run compute. The motto is to always use the cloud orchestrator that already exists or is in use.
Furthermore, Starlake supports templating for customizing the DAG generation using Jinja2 and Python. This helps load similar tasks with the same template, helping to maintain consistency across a large codebase.
DAG generation relies on command line tools, configurations, templates, and the starlake-orchestration framework to manage dependencies. Templates for data loading and transformation can be customized with runtime parameters using Python variables like jobs and user_defined_macros. Dependencies between tasks can be managed either inline (generating all dependencies) or through external state changes using Airflow datasets or Dagster Assets.
The best part is that users can schedule advanced schedules with code-free templating, also called no-code—you just select one of the predefined/custom orchestrator templates and let Starlake generate and deploy your DAGs on your selected orchestrator. See some examples in Orchestration Tutorial.
Furthermore, you get intelligent and visual dependency management with parallel execution when needed, and automated error handling and recovery. It's a key component of Starlake, as it not only defines the data stack via flexible configurations but can also run it with whatever execution engine your data organization uses.
Multi-Engine Flexibility and Cross-Platform Support
What does that mean? This concept is what differentiates it from normal data stacks that can run only a proprietary engine. This way you have a well-defined configuration for your data stack and business logic, but with the flexibility to exchange to newer or faster engines.
Cross-engine support to use any compute you want. As you can see in the image, you could use Snowflake or hook it up to Excel.
Further, you are not vendor-locked in—you can use different engines when needed or can change if you have to because of an organizational decision. By default, Starlake lets you specify your default engine for your entire project while also giving you the flexibility to override it on a per-model basis.
Let's say you need the native warehouse engine in production for speed and security reasons, while leveraging DuckDB in the development environment or using Spark to process thousands of XML files in the test environment. Starlake is also cross-engine capable, enabling transformations that query one data warehouse and write results to another. This is especially useful for export tasks to formats like CSV, Parquet, or Excel, as well as for integrations with external analytical or operational databases.
The last step is deploying your project. Maybe you run it locally with Docker and want to run it on Kubernetes or Starlake Cloud. For that, you can simply copy the configurations and be up to speed. That's the beauty of being declarative.
Visualization is usually not covered by a declarative data stack, but you can plug in any notebook, data apps, or business intelligence tools to use your created data marts or data artifacts.
Every data analytics project needs a visualization tool. Starlake leaves this open, so you could use any you want.
So whether you're a business user, data analyst, or data engineer, Starlake, with its declarative approach and low-code interface, makes it easy for everyone to create a sophisticated data platform with minimal configuration and all the bells and whistles included.
It allows efficient data transformation with the engine of your choice, supporting SQL and Python defined in YAML. It provides automatic handling of advanced write methodologies such as incremental and SCD2, built-in support for complex data types and error handling, and everything is version-controllable with simple YAML. Best of all, Starlake is fully open-source.
I believe the future is declarative data engineering, and Starlake can play a big part in this. Some also talk about the move From Data Engineer to YAML Engineer and explain how declarative stacks free up engineers to focus on higher-value work.
In Part 3, we'll discuss use cases such as transpiling SQL between dialects and data quality and validation with expectations in action. We'll demonstrate the built-in, declarative security features and showcase DAG generation using templates that integrate with Airflow, Dagster, and Snowflake tasks out of the box, including column-level lineage support. We'll also analyze how the end goal of moving toward English engineering through LLMs could look—a road to self-service data platforms with a declarative backbone.
I hope you enjoyed this. Please let me know in the comments or write me if you have any feedback or experiences with declarative data stacks.
Want to get started with Starlake? Check out the GitHub repo or get started with a demo on demo.starlake.ai. Again, Starlake is fully open-source—not only its engine but also SQL transpilers and used tools—but you can also use its cloud hosting to get started immediately. If you use VS Code, check out the extension for this too.
Dbt recently launched Dbt Fusion, a performance-oriented upgrade to their transformation tooling.
It’s faster, smarter, and offers features long requested by the community — but it comes bundled with tighter control, paid subscriptions, and runtime lock-in.
We've been there all along but without the trade-offs.
At Starlake, we believe great data engineering doesn’t have to come with trade-offs.
We've taken a different approach from the start:
✅ Free and open-source core (Apache 2)
✅ No runtime lock-in
✅ Auto-generated orchestration for Airflow, Dagster, Snowflake Tasks, and more
✅ Production-grade seed and transform tools
Disclaimer: Dbt offers a free tier for teams with fewer than 15 users.
This comparison focuses on organizations with more than 15 users, where most of Dbt Fusion’s advanced features are gated behind a paid subscription.
Fast engine: Starlake uses a Scala-based engine for lightning-fast performance, while Dbt Fusion relies on a Rust-based engine.
Database offloading: Dbt Fusion uses SDF and DataFusion, while Starlake leverages JSQLParser and DuckDB for cost-effective SQL transformations and database offloading.
Native SQL comprehension: Both tools enable real-time error detection, SQL autocompletion and context-aware assistance without needing to hit the data warehouse. The difference ? With Dbt Fusion, it’s a paid feature. With Starlake, it’s free and open.
State-aware orchestration: Dbt Fusion's orchestration is limited to Dbt Saas Offering, while Starlake generates DAGs for any orchestrator with ready ones for Airflow, Dagster, and Snowflake Tasks.
Lineage & governance: Dbt Fusion offers lineage and governance features in their paid tier, while Starlake provides these capabilities for free and open.
Web-based visual editor: Dbt Fusion comes with aYAML editor only as part of their paid tier, while Starlake offers a in addition to a YAML editor, a free web-based visual editor.
Platform integration: aka. Consistent experience across all interfaces, Dbt Fusion's platform integration is available in their paid tier, while Starlake provides free integration with various platforms.
Data seeding: Dbt Fusion supports CSV-only data seeding, while Starlake offers full support for various data formats (CSV, JSON, XML, Fixed Length ...) with schema validation and user-defined materialization strategies.
On-Premise / BYO Cloud: Dbt Fusion does not offer an on-premise or BYO cloud option, while Starlake supports both allowing you to use the same tools and codebase across environments.
VSCode extension: Dbt Fusion's VSCode extension is free for up to 15 users, while Starlake's extension is always free.
SaaS Offering: Dbt Fusion is a SaaS offering, while Starlake is open-source with a SaaS offering coming soon.
MCP Server: Dbt Fusion's MCP Server requires a paid subscription for tools use, while Starlake provides a free full-fledged MCP Server for managing your data pipelines.
SQL Productivity tools: Dbt comes with DBT Canva, a paid product, at Starlake this is handled by Starlake Copilot through english prompts, which is free and open-source.
Feature
**Dbt Fusion **
Starlake.ai
Fast engine
Yes (Rust-based)
Yes (Scala-based)
State-aware orchestration
Limited to Dbt own orchestrator
Yes on Airflow, Dagster, Snowflake Tasks, etc.
Native SQL comprehension
Based on SDF
Based on JSQLParser/JSQLTranspiler
Database offloading
DataFusion
DuckDB
Lineage & governance
Paid tier
Free
Web-based visual editor
No
Yes and always free
Platform integration
Paid tier
Free
Data seeding
For tiny CSV-only
Production grade support for various formats with schema validation
Dbt Fusion makes bold claims — and to their credit, they’ve pushed the modern data stack forward.
But openness without freedom is just marketing.
Starlake gives you both.
✅ Open-source.
✅ Free to use.
✅ Orchestrate anywhere.
👉 Ready to experience the freedom of open-source, no lock-in data engineering ?
Visit starlake.ai, check out our documentation to get started or join our community to learn more.
Imagine building enterprise data infrastructure where you write 90% less code but deliver twice the value. This is the promise of declarative data stacks.
The open and modern data stack freed us from vendor lock-in, allowing teams to select best-of-breed tools for ingestion, ETL, and orchestration. But this freedom comes at a cost: fragmented governance, security gaps, and potential technical debt when stacking disconnected tools across your organization.
On the flip side, closed-source platforms offer unified experiences but trap you in their ecosystems where you can't access the code or extend beyond their feature sets in case of need.
What if we could have the best of both worlds?
Enter declarative data stacks – open-source solutions that seamlessly integrate powerful orchestration tools like Airflow and Dagster while covering your entire data lifecycle. These are complete data platforms with "batteries included" where configuration replaces coding, dramatically reducing complexity while implementing best practices by default.
In this article, we'll explore how declarative data stacks manage enterprise data complexity. You'll discover how Starlake, an open-source declarative data stack, enables data transformations through simple configurations, helping teams deliver production-ready platforms in days instead of months while automatically maintaining governance and lineage.
At its core, Starlake serves as your data warehouse orchestrator – a unified control center that manages your entire data ecosystem through a single, coherent lineage. Not just a tool, but an end-to-end OSS data platform that makes "configure, don't code" a practical reality for enterprise teams.
A declarative data stack is essentially an end-to-end data engineering tool that is made for complexity. It has all the features you need included. It extracts, loads, transforms, and orchestrates. The mantra: Code less, deliver more.
What's the catch? You need to align with a common configuration style. You need a framework, a tool, something that abstracts and does the hard work, so that we, the users, can simply configure and run it. This is where YAML comes in. Some also call it the YAML Engineer.
In this Part 1, we will go through the benefits and anatomy of declarative data stacks, and see how Starlake can help us with that. In Part 2 we'll have a look at an end-to-end data engineering project that does ingestion from any configurable source, using SQL transformation and orchestrating it with Airflow, Dagster, or even Snowflake Tasks (you choose!), showing a declarative data stack in action.
And then finally, we'll choose a BI dashboard to visualize the data (not part of Starlake).
The Evolution Toward Declarative Data Engineering
If we look back at where we come from, we can see that 20 years back, everyone just picked a vendor like SAP, Oracle, or Microsoft, and ran with their database or business intelligence solutions. You had lots of options, but if you needed anything specific, you had to request that feature and hope someone implemented it. You were captured in a monolithic system.
Because these were widely spread, you had a good chance that what you wanted was already there. But there was always this one customer that wanted that one extra thing. That's why a little later, the boom with open-source happened. All of a sudden, plenty of US startups were sharing their tools like Hadoop and its whole ecosystem. Everyone got used to sharing their code and became excited about solving tough problems together.
This also took over the data space and became one of the starting points for data engineering when Maxime Beauchemin started sharing his trilogy about functional data engineering. More and more tools got open-sourced and this is where we landed a while back with the explosion of tools and the Modern Data Stack, or Open Data Stack, a modular system. Usually the deployment and DevOps involved are quite a massive effort; think Terraform, Helm Charts, or Kustomize and how these democratized declarative engineering over the last decades.
Today we are entering the next phase of the cycle. We are back to one platform ruling them all, or better, bringing together the strengths from both of these worlds: having one platform integrated with open-source tools. But how do we achieve this? Exactly, you guessed it right, with declarative data stacks.
This transition from a monolithic to a modular system, back to a monolithic platform but with OSS plug-and-play tools to choose from with integrated templates, is a great evolution learning from the past. And declarative data stacks are the key to that.
But maybe you haven't heard of that term, or are unsure what it means. I have written about it at length in The Rise of the Declarative Data Stack, but here is the short version of it:
A declarative data stack is a set of tools and, precisely, its configs can be thought of as a single function such as run_stack(serve(transform(ingest))) that can recreate the entire data stack.
Instead of having one framework for one piece, we want a combination of multiple tools combined into a single declarative data stack. Like the Modern Data Stack, but integrated the way Kubernetes integrates all infrastructure into a single deployment, like YAML.
We focus on the end-to-end data engineering lifecycle, from ingestion to visualization. But what does the combination with declarative mean? Think of functional data engineering, which leaves us in a place of confident reproducibility with little side effects (hopefully none) and uses idempotency to restart functions to recover and reinstate a particular state with conviction or rollback to a specific version.
At its core, we can define the full data stack with a single configuration file (or files). And instead of defining the how, we can configure what we want to achieve. Essentially code less and deliver more with the benefit of a more reproducible and maintainable data stack.
Declarative data stacks also break free from black boxes of different OSS tools that you have a hard time integrating. Instead, you get a data-aware data platform that integrates through parametric configuration into the end-to-end data pipeline.
Unlike Airflow, where each task has no idea what is happening inside of it, it's a black box. As more complex data platforms become the norm, knowing if a task has finished or not is not enough. With a declarative approach, you focus more on the what, the data assets. This means we define them, their logic, dependencies, down to their column-level lineage and types. This opens up the black box for us in an easy and approachable way, mainly in YAML.
The YAML configuration approach makes the internal workings more explicit and accessible, rather than hiding them, making the configuration and produced assets transparent and accessible to us and our users.
The YAML configs also make it approachable to non-programmers, as YAML is the universal configuration language. YAML is also easy to integrate with LLMs, more so as it's a superset of JSON and easily integrates with JSON Schema. This means each YAML can be converted to JSON and integrated with the powerful data serialization language of JSON Schema. This leads to a (longer) context window where AI and humans can iterate on and integrate into any code editor or architecture. Ultimately, it helps to make English engineering a reality.
But what does that data platform include, and what's the anatomy of such a data stack? A declarative data stack does not only support one part of the data engineering lifecycle but the entire process end-to-end.
We go from extracting data to orchestrating them all in one platform:
Extract: Configuration-driven data ingestion
Load: Zero-code data loading with built-in validations
Transform: SQL-based transformations with automatic optimizations
Orchestrate: Integration with existing workflow managers
Visualization: Present and visualize created data assets
Lineage: Visibility across the entire stack
If you will, these are the core bones and skeleton of a declarative data stack. There are now many ways one could implement this. In the following chapters, we'll analyze how Starlake implemented these components, and how it can help us support complex data landscapes.
Starlake: An Open Source Declarative Data Platform
Starlake gets you all the discussed benefits of a declarative data stack in one single platform, configurable by YAML. It offers a powerful open-source solution to embrace declarative data engineering end-to-end.
In a nutshell, Starlake is a comprehensive declarative data platform that:
Is based in France, is entirely open-source, and had its first commit on May 21 2018 by Hayssam Saleh (LinkedIn).
Runs on JVM (built with Scala) for cross-platform compatibility, bringing type safety and performance
Uses a YAML-based configuration approach (similar to how Terraform works for infrastructure)
Covers the entire data lifecycle: extract, load, transform, test, and orchestrate
Supports multiple data warehouse engines (Snowflake, BigQuery, Databricks, etc.)
Integrates with popular orchestrators like Airflow, Dagster, Snowflake Tasks, and Databricks scheduler (coming soon)
Eliminates complex coding with a "declare, don't code" philosophy
Features built-in data governance, validation, and lineage tracking
Enables development in-memory and local DuckDB, as well as deployment to any supported platform
It has automated data quality checks and validation, native integration with major data warehouses, and no-code and low-code paradigms support. It also comes with enterprise-grade security and governance out of the box and supports both batch and real-time processing.
Starlake bridges the gap between open-source flexibility and enterprise-ready data platforms, allowing organizations to build robust data pipelines with minimal code while maintaining complete visibility and control. It builds and orchestrates data warehouses with the complexity of data in mind from the get-go.
But why would you use Starlake at a large enterprise? What are the immediate benefits? In condensed form, you could say it helps address these three main problems that we face in the field of data engineering:
Overwhelming complexity in managing data pipelines
Inefficiencies in transforming and orchestrating data workflows
Lack of robust governance and data quality assurance
Starlake simplifies the data management effort with configuration-driven ingestion, transformation, and orchestration, and reduces manual implementation of each data pipeline.
This enhances data quality and the overall reliability of the platform with enforced governance, schema validation, rules, and SLAs across the system. It accelerates time to insights and opens up opportunities to create additional data pipelines with less technical people through the UI and configuration interface.
If we compare it to traditional ETL tools, the table below will help us understand the differences:
Feature
Starlake.ai
Traditional ETL Tools
Benefits
Core Architecture
Declarative (YAML-based)
Imperative (code-heavy)
Reduced maintenance burden, improved readability
No-Code Ingestion
✅
❌ (requires custom coding)
Faster implementation, accessible to non-programmers
Declarative Transformations
✅
❌
Simplified maintenance, consistent patterns
Automated Orchestration
✅ (integrates with Airflow/Dagster)
❌ (requires manual setup)
Reduced setup time, automated dependency management
Built-in Governance
✅
❌
Enforced data quality and consistency
Cross-Engine Capabilities
✅
❌
Flexibility to work across different platforms
Multi-Engine Support
��✅
❌
Prevents vendor lock-in
Automated Schema Evolution
✅
❌
Adapts to changing data structures automatically
SQL Transpilation
✅
❌
Write once, deploy anywhere capability
Local Development
✅ (with DuckDB)
❌
Faster development cycles, reduced cloud costs
Data Quality Validation
✅ (built-in)
⚠️ (limited/add-on)
Higher data reliability
End-to-End Lineage
✅ (column-level)
⚠️ (typically table-level)
Enhanced visibility and troubleshooting
Row/Column Level Security
✅
⚠️ (often requires add-ons)
Better compliance capabilities
Gen AI Readiness
✅ (via JSON Schema)
❌
Future-proof architecture
Learning Curve
Moderate (YAML)
High (multiple languages/tools)
Faster team onboarding
Implementation Time
Fast
Slow
Quicker time to insights
Maintenance Burden
Low
High
Reduced technical debt
In the end, it manages complexity and the return on investment in the platform grows with rising complexity. The reason is the declarative nature and the encapsulation of complexity into the platform (Starlake), allowing the data engineer and user of the platform to focus on the business requirements and analytics.
Contrast that with manually writing imperative Python scripts to schedule your data pipeline or managing your infrastructure by manually installing multiple tools and making them work altogether. This is the main challenge the current landscape faces, and the hidden cost of imperative data work.
That's why integrated systems are on the rise and where configuration-driven stacks bridge the gap to become easier to maintain and more reliable.
If you have a simple POC, or you know for a fact that the platform will never get wider use or grow bigger, or the requirements are in constant change, then it's easier to custom-make an imperative solution. Though you can still use Starlake to quickly start up with all batteries included, it's still a better fit to abstract a big complex data landscape into a manageable data platform, with an integrated governed solution.
If your focus is on visualization, Starlake comes with no presentation tool, though it can be easy to hook up one to the generated data assets. Best would be to stay in the code-first and declarative approach with BI solutions such as Rill, Evidence, or Lightdash.
Starlake is especially strong with large enterprises, which shows with the current customer base, mostly large enterprises with high volumes (100 GB/day and 100 TB in BigQuery), multi-cloud such as Google Cloud and reports on Azure, or on the other spectrum, streaming-like requirements with new small files every minute, ingested into Redshift and visualized in Superset.
Starlake spans across multiple verticals within the data landscape and isn't limited to one aspect of data engineering. Just as YAML has become the universal configuration language for various domains, declarative data stacks integrate several critical verticals of the data engineering ecosystem under a unified configuration approach.
Orchestration: Rather than writing complex DAG code, workflows are defined in YAML and automatically translated to Airflow or Dagster execution plans. This abstracts away the complexity of pipeline scheduling and dependency management.
Transformation: SQL is already declarative by nature, but Starlake enhances it with automated optimizations and transpilation across different warehouse dialects—write once, run anywhere.
Infrastructure: Similar to how Terraform revolutionized infrastructure management, Starlake applies declarative principles to data infrastructure, enabling version-controlled data assets.
API Integration: Much like OpenAPI Specification uses YAML to define REST APIs, Starlake allows declarative configuration of data sources and destinations.
Governance: Data quality rules, schema validation, and access controls are all defined declaratively rather than scattered across multiple codebases.
That's it, that's why you shouldn't code but configure if you want to optimize for a large enterprise. This article is part one of three. Before we check Starlake in action in Part 2 and analyze what's possible today with declarative data stacks as well as the future of it, including how to integrate well with the latest GenAI and GenBI capabilities, let's wrap up this article.
We have learned that declarative data stacks represent a paradigm shift in enterprise data engineering - "Declare your intent, don't code it." By embracing configuration over custom coding, organizations gain reproducibility, maintainability, and governance without sacrificing flexibility. With tools like Starlake, you can develop and test locally on DuckDB using your target warehouse's SQL dialect, reducing costs and enabling faster development cycles while ensuring consistent quality through automated testing.
Breaking free from black boxes doesn't mean abandoning the open data stack, but rather integrating best-in-class tools under a unified, configuration-driven approach. The result is a data platform that scales with your complexity, reduces technical debt, and democratizes data engineering by making it accessible to YAML engineers alongside traditional coders. As data landscapes grow increasingly complex, the declarative approach offers a sustainable path forward that balances enterprise requirements with development agility.
I believe the future of data engineering will change significantly, but with a declarative data stack, we are ready for whatever changes come with an adaptable configuration-first system that nicely abstracts implementation logic from business requirements. This allows the future of data pipeline development to be adaptable, governed, and ready to evolve with organizational needs.
I'm Julien, freelance data engineer based in Geneva 🇨🇭.
Every week, I research and share ideas about the data engineering craft.
Not subscribed yet?
👨🏽💻 echo {YOUR_INBOX} >>
Subscribe
Software has always been a matter of abstraction.
Over the years, the industry has constructed layers upon layers to develop increasingly complex software.
The same trend is happening in the data world.
More and more tools are emerging to standardize the construction of data pipelines, pushing towards a declarative paradigm.
Engineers spend less and less time coding and more and more parametrizing and coordinating functional building blocks.
In the first version of this post (co-written with Benoît Pimpaud), we highlighted signs of this trend (AWS Pipes, Snowflake Dynamic Tables, and YAML-driven orchestration with Kestra)
We called it provocatively: From Data Engineer to YAML Engineer.
It has, therefore, limited awareness of execution history and timing.
Determining which models need to run is challenging, requiring comparisons of run artifacts.
SQLMesh advances the declarative paradigm by introducing stateful orchestration.
It executes models and maintains a complete execution history, automatically determining what needs to be re-run based on code changes and data freshness.
All this happens without requiring manual DAG configuration in your orchestrator or job scheduler.
You say:
MODEL ( name my.model, cron '5 4 1,15 * *' -- Run at 04:05 on the 1st and 15th of each month ) SELECT * FROM ...
And SQLMesh tracks the last run, checks the model frequency, and decides whether to execute.
It bridges the gap between transformation and orchestration—you stay in the declarative world the whole time.
3- Declarative BI: Rill
Let's continue our journey down the data flow—this time arriving in the BI world.
The software engineering mindset seems to stop with traditional BI tools just before BI begins.
Cross that frontier, and you'll be met with endless clicking: there is no version control, reproducible environments, or modular logic.
You're left building dashboards by hand, from scratch, every single time.
I'm excited to see BI finally embrace software engineering principles through BI-as-code tools like Rill, Light Dash, and Evidence.
A Rill project, for example, consists of YAML files defining dashboards, metrics, and sources:
You get interactive charts and dashboards that are reproducible, version-controlled, and easy to share across environments.
4- Declarative Data Platform: Starlake
Let’s flip the script and look at Starlake, an open-source tool combining both ingestion and transformation in a unified declarative framework.
Starlake doesn’t rely on external libraries or frameworks.
Instead, they've built their own ingestion engine, transformation framework (with a custom SQL parser), and YAML interface.
This unified approach allows users to define their entire pipeline in a single YAML file:
Building both ingestion and transformation frameworks from scratch makes them direct competitors to many actors.
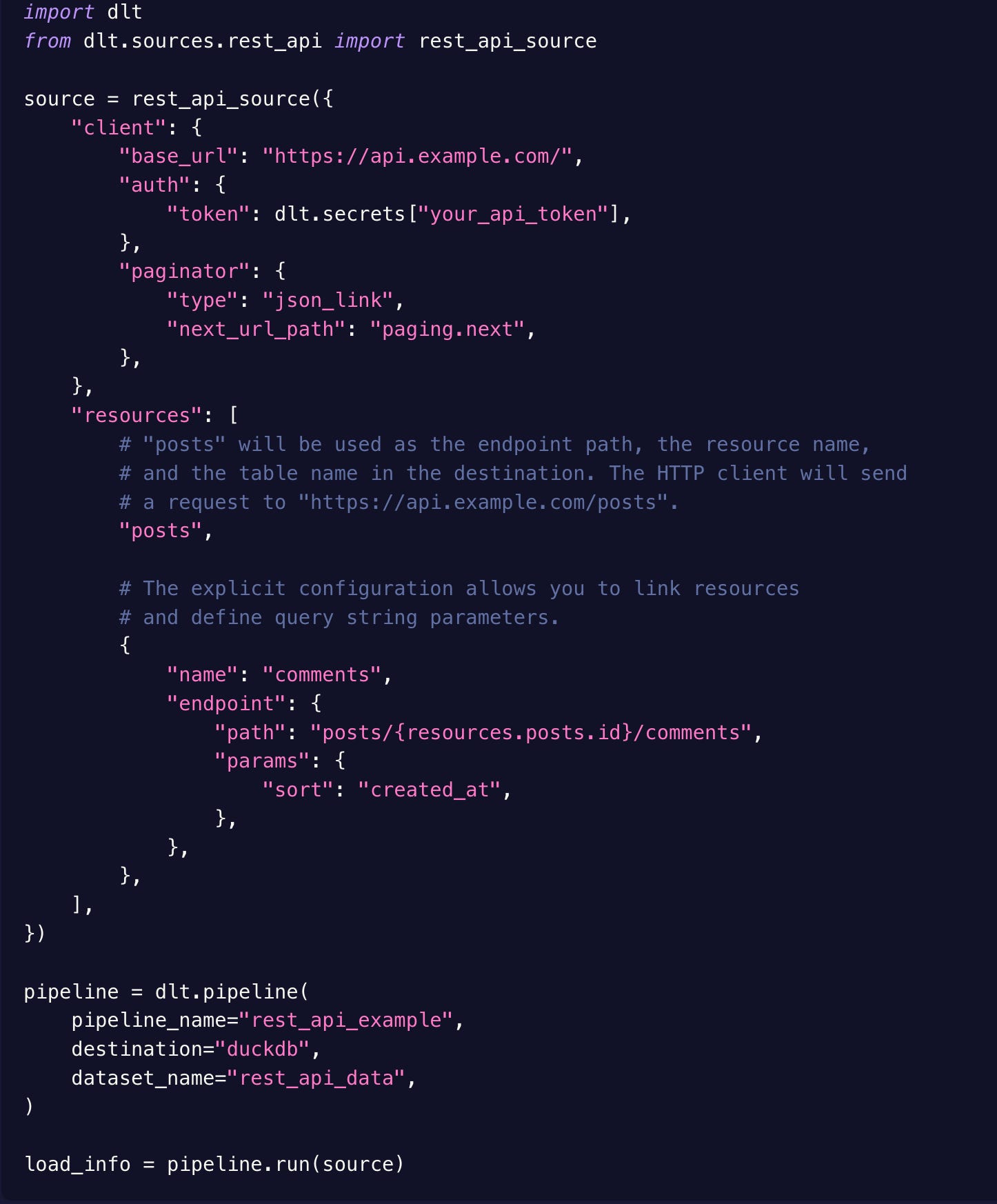
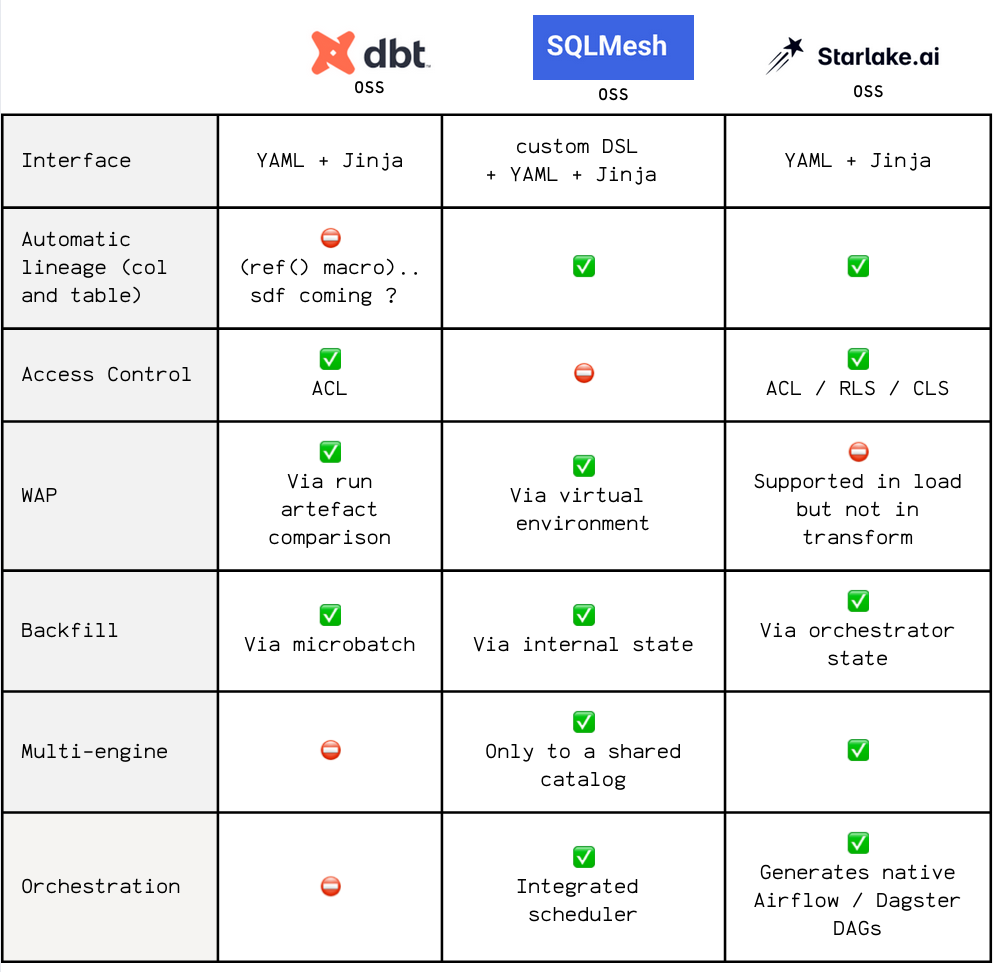
Here's a recap of how they position themselves vs dlt for the ingestion:
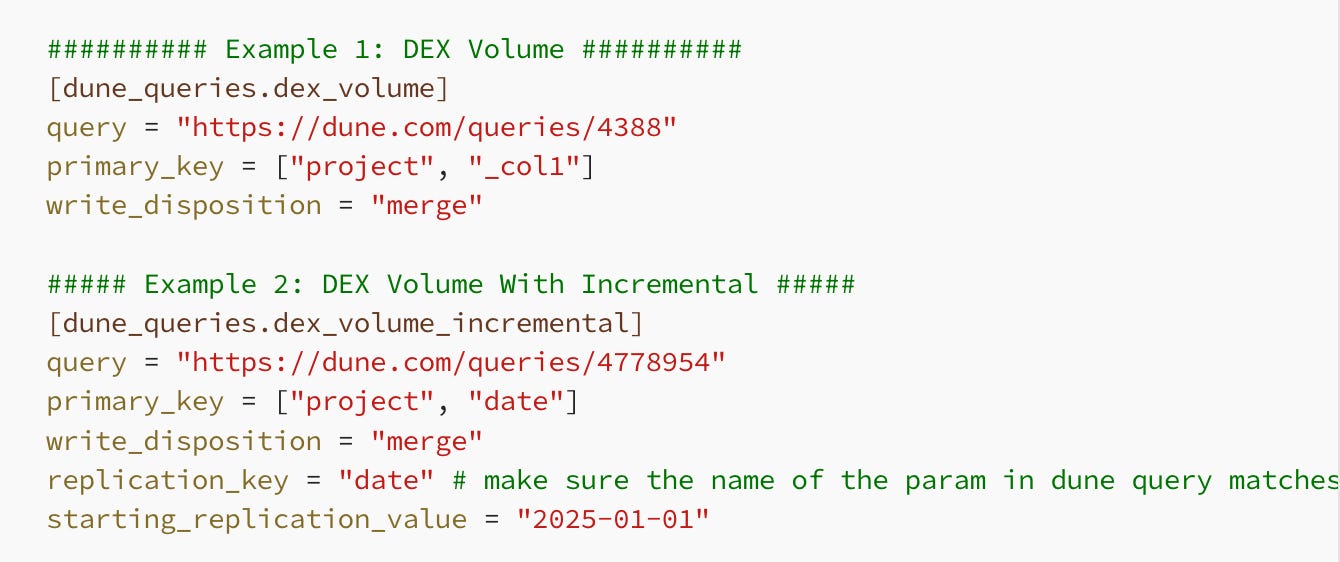
And vs dbt and SQLMesh for the transformation:
Finally, the open source version of Starlake comes with a UI where users can directly edit the YAML config and SQL transformation (with an AI assistant)
Starlake UI is open source as well
The main advantage of such an approach is that it provides a consistent interface for the whole data lifecycle without the need to learn and manage many different tools.
Check out their GitHub to get started with Starlake or learn more.
Thanks for reading, and thanks, Starlake, for supporting my work and this article.
We're excited to unveil Starlake.ai, a groundbreaking platform designed to streamline your data workflows and unlock the full potential of your data. 🚀
When loading files into BigQuery,
you may need to split your data into multiple partitions to reduce data size,
improve query performance, and lower costs.
However, BigQuery’s native partitioning only supports columns with date/time or integer values.
While partitioning on string columns isn’t directly supported,
BigQuery provides a workaround with wildcard tables, offering nearly identical benefits.
In this example, we demonstrate how Starlake simplifies the process by seamlessly
loading your data into wildcard tables.
One of the key advantages of Starlake is its ability to handle incremental models without
requiring state management.
This is a significant benefit of it being an integrated declarative data stack.
Not only does it use the same YAML DSL for both loading and transforming activities,
but it also leverages the backfill capabilities of your target orchestrator.
In today's data-driven landscape, ensuring the reliability and accuracy of your data warehouse is paramount. The cost of not testing your data can be astronomical, leading to critical business decisions based on faulty data and eroding trust.
The path to rigorous data testing comes with its own set of challenges. In this article, I will highlight how you can confidently deploy your data pipelines by leveraging Starlake JSQLTranspiler and DuckDB, while also reducing costs. we will go beyond testing your transform usually written in SQL and see how we can also test our Ingestion jobs.


 Example of how to load data and its configurations in Starlake GUI
Example of how to load data and its configurations in Starlake GUI
 An example of the many options when loading data
An example of the many options when loading data Starlake worksheet data transformation example.
Starlake worksheet data transformation example. Preview our data aggregation—or hit transpiled or lineage to see more detailed information.
Preview our data aggregation—or hit transpiled or lineage to see more detailed information.` above).") An example of column-level lineage with its dependencies and an overview of your data assets in the web UI. Hovering with the mouse will reveal the transformation applied (see
An example of column-level lineage with its dependencies and an overview of your data assets in the web UI. Hovering with the mouse will reveal the transformation applied (see  Cross-engine support to use any compute you want. As you can see in the image, you could use Snowflake or hook it up to Excel.
Cross-engine support to use any compute you want. As you can see in the image, you could use Snowflake or hook it up to Excel.