Dbt Fusion vs. Starlake AI: Why Openness Wins

Starlake vs. Dbt Fusion: Why Openness Wins
Dbt recently launched Dbt Fusion, a performance-oriented upgrade to their transformation tooling.
It’s faster, smarter, and offers features long requested by the community — but it comes bundled with tighter control, paid subscriptions, and runtime lock-in.
We've been there all along but without the trade-offs.
At Starlake, we believe great data engineering doesn’t have to come with trade-offs.
We've taken a different approach from the start:
✅ Free and open-source core (Apache 2)
✅ No runtime lock-in
✅ Auto-generated orchestration for Airflow, Dagster, Snowflake Tasks, and more
✅ Production-grade seed and transform tools
Let’s break it down.
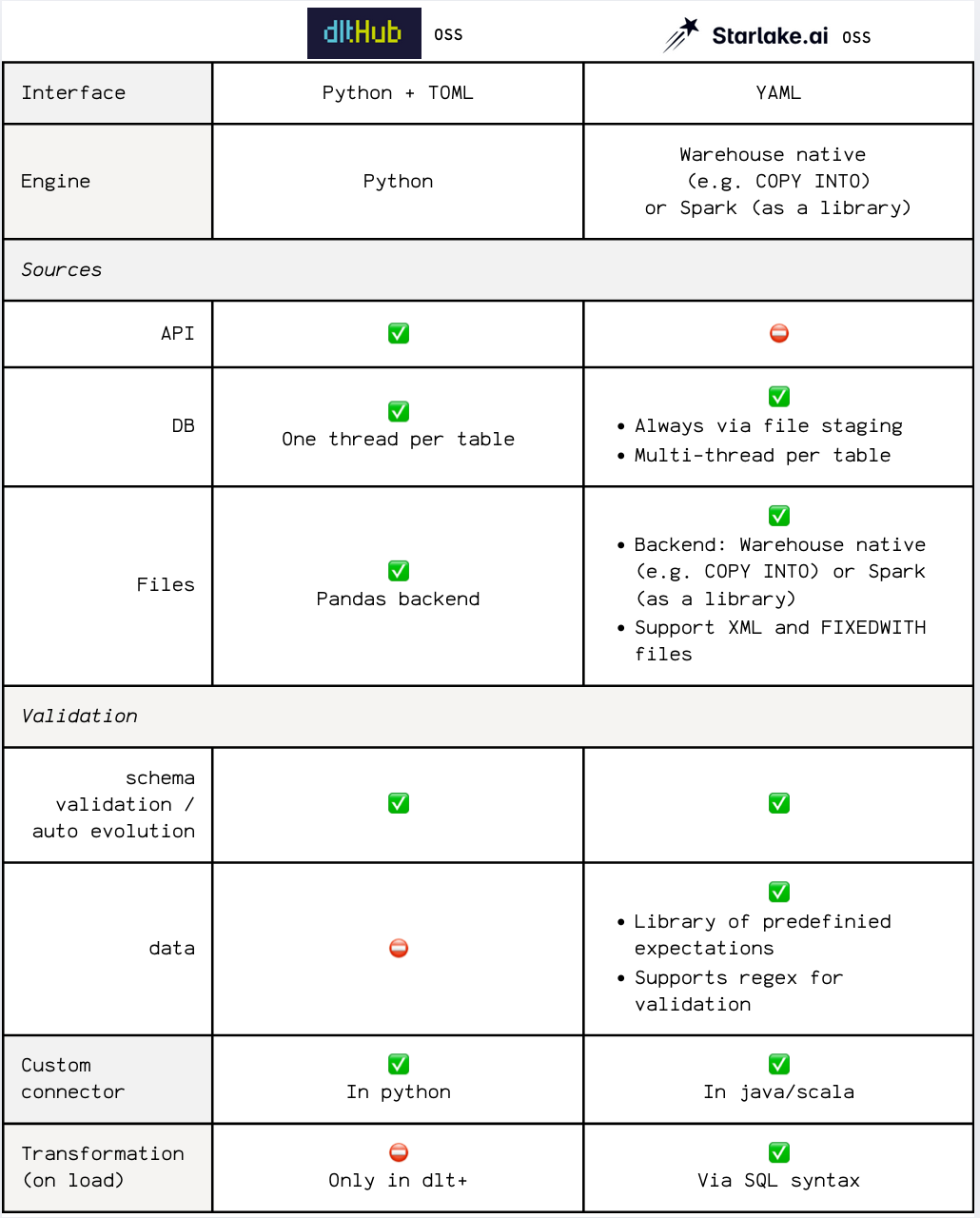
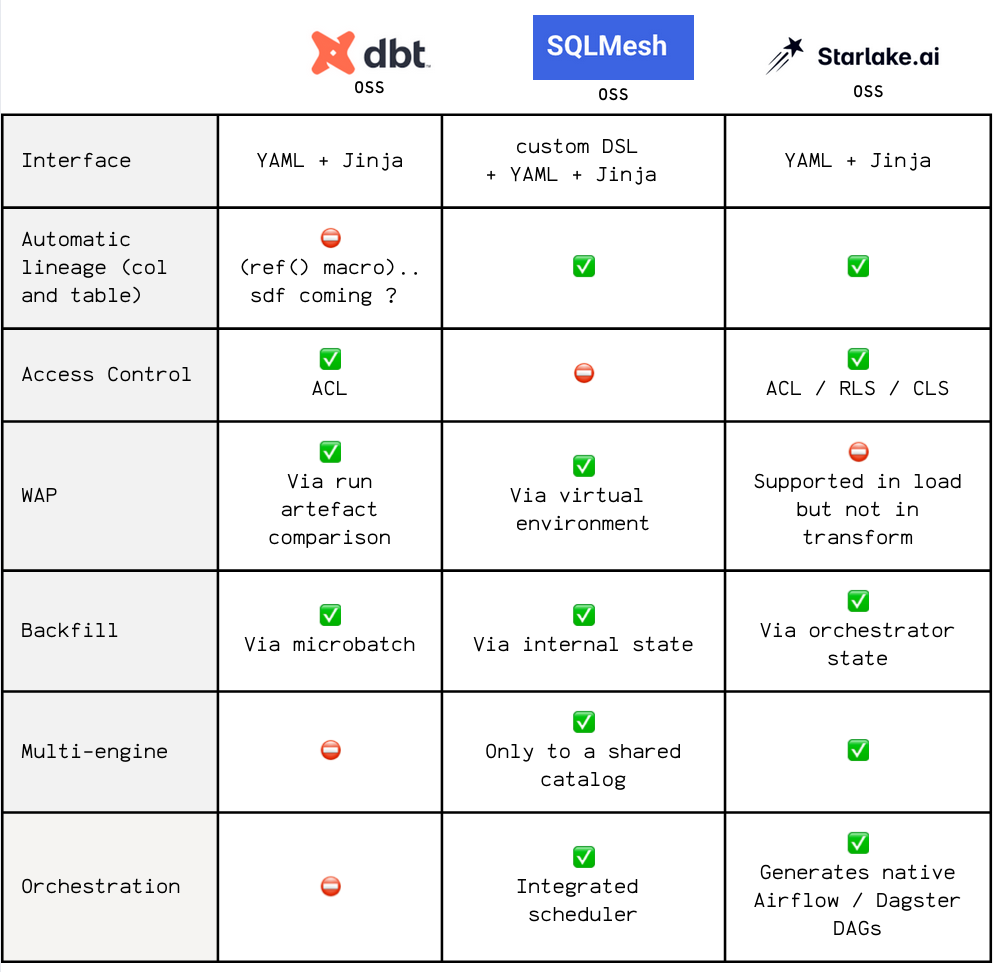
Feature-by-Feature Comparison
Disclaimer: Dbt offers a free tier for teams with fewer than 15 users. This comparison focuses on organizations with more than 15 users, where most of Dbt Fusion’s advanced features are gated behind a paid subscription.
- Fast engine: Starlake uses a Scala-based engine for lightning-fast performance, while Dbt Fusion relies on a Rust-based engine.
- Database offloading: Dbt Fusion uses SDF and DataFusion, while Starlake leverages JSQLParser and DuckDB for cost-effective SQL transformations and database offloading.
- Native SQL comprehension: Both tools enable real-time error detection, SQL autocompletion and context-aware assistance without needing to hit the data warehouse. The difference ? With Dbt Fusion, it’s a paid feature. With Starlake, it’s free and open.
- State-aware orchestration: Dbt Fusion's orchestration is limited to Dbt Saas Offering, while Starlake generates DAGs for any orchestrator with ready ones for Airflow, Dagster, and Snowflake Tasks.
- Lineage & governance: Dbt Fusion offers lineage and governance features in their paid tier, while Starlake provides these capabilities for free and open.
- Web-based visual editor: Dbt Fusion comes with aYAML editor only as part of their paid tier, while Starlake offers a in addition to a YAML editor, a free web-based visual editor.
- Platform integration: aka. Consistent experience across all interfaces, Dbt Fusion's platform integration is available in their paid tier, while Starlake provides free integration with various platforms.
- Data seeding: Dbt Fusion supports CSV-only data seeding, while Starlake offers full support for various data formats (CSV, JSON, XML, Fixed Length ...) with schema validation and user-defined materialization strategies.
- On-Premise / BYO Cloud: Dbt Fusion does not offer an on-premise or BYO cloud option, while Starlake supports both allowing you to use the same tools and codebase across environments.
- VSCode extension: Dbt Fusion's VSCode extension is free for up to 15 users, while Starlake's extension is always free.
- SaaS Offering: Dbt Fusion is a SaaS offering, while Starlake is open-source with a SaaS offering coming soon.
- MCP Server: Dbt Fusion's MCP Server requires a paid subscription for tools use, while Starlake provides a free full-fledged MCP Server for managing your data pipelines.
- SQL Productivity tools: Dbt comes with DBT Canva, a paid product, at Starlake this is handled by Starlake Copilot through english prompts, which is free and open-source.
| Feature | **Dbt Fusion ** | Starlake.ai |
|---|---|---|
| Fast engine | Yes (Rust-based) | Yes (Scala-based) |
| State-aware orchestration | Limited to Dbt own orchestrator | Yes on Airflow, Dagster, Snowflake Tasks, etc. |
| Native SQL comprehension | Based on SDF | Based on JSQLParser/JSQLTranspiler |
| Database offloading | DataFusion | DuckDB |
| Lineage & governance | Paid tier | Free |
| Web-based visual editor | No | Yes and always free |
| Platform integration | Paid tier | Free |
| Data seeding | For tiny CSV-only | Production grade support for various formats with schema validation |
| On-Premise / BYO Cloud | Not available | Yes |
| VSCode extension | Paid tier | Always free |
| MCP Server | Paid tier | Yes (free) |
| SQL Productivity tools | Paid product (DBT Canva) | Free and open-source (Starlake Copilot) |
| SaaS Offering | Yes | Coming soon |
Strategy Matters As Much As Features
Many tools advertise flexibility - but in practice, they quietly funnel users into proprietary runtimes.
Dbt Fusion is no exception.
Their orchestrator is gated behind a paid cloud platform, and most features require a subscription once your team grows.
Starlake doesn’t play that game.
We provide:
- A single declarative YAML layer for extract, ingest, transform, validate, and orchestrate
- One config = Multiple warehouses (BigQuery, Snowflake, Redshift…)
- Your orchestrator = Your choice, fully integrated
- Auto-generated DAGs, no manual workflow wiring
- Run it locally, in the cloud, or anywhere in between
Who Should Choose Starlake?
Starlake is ideal for:
- Data teams who want speed without lock-in
- Enterprises who need production-grade on premise and cloud data pipelines without vendor lock-in
- Startups who want open-source pricing and cloud-scale performance
- Teams who prefer Airflow, Dagster, Google Cloud Composer, AWS Managed Airflow, Asttronomer, Snowflake Tasks, or any engine they already trust
Whether you're building your first pipeline or managing thousands across clouds, Starlake lets you grow on your terms.
Final Thought
Dbt Fusion makes bold claims — and to their credit, they’ve pushed the modern data stack forward.
But openness without freedom is just marketing.
Starlake gives you both.
✅ Open-source.
✅ Free to use.
✅ Orchestrate anywhere.
👉 Ready to experience the freedom of open-source, no lock-in data engineering ? Visit starlake.ai, check out our documentation to get started or join our community to learn more.