From Data Engineer to YAML Engineer (Part II)
Bonjour!
I'm Julien, freelance data engineer based in Geneva 🇨🇭.
Every week, I research and share ideas about the data engineering craft.
Not subscribed yet?
👨🏽💻 echo {YOUR_INBOX} >>Subscribe
Software has always been a matter of abstraction.
Over the years, the industry has constructed layers upon layers to develop increasingly complex software.
The same trend is happening in the data world.
More and more tools are emerging to standardize the construction of data pipelines, pushing towards a declarative paradigm.
Engineers spend less and less time coding and more and more parametrizing and coordinating functional building blocks.
In the first version of this post (co-written with Benoît Pimpaud), we highlighted signs of this trend (AWS Pipes, Snowflake Dynamic Tables, and YAML-driven orchestration with Kestra)
We called it provocatively: From Data Engineer to YAML Engineer.
From Data Engineer to YAML Engineer -----------------------------------
Julien Hurault and Benoit Pimpaud
·
November 22, 2023

Software has always been a matter of abstraction.
One year later, the movement has only accelerated.
So, let’s keep the exploration going with:
- Declarative ingestion & dlt
- Declarative transformation & SQLMesh
- Declarative BI & Rill
- Declarative data platform & Starlake
—
Thanks to Starlake for sponsoring this post and supporting such a discussion on declarative data tooling.
ELT tools have always been declarative—you define your connector and target and let the tool handle the rest.
And for common sources with well-supported, battle-tested connectors, this works great:

However, when faced with an obscure API, legacy MSSQL server, or an internal system lacking a reliable connector...
You're forced to write custom Python code to handle pagination, retries, and other complexities.
This is the main frustration with data ingestion: it's often all or nothing.
You either have a smooth declarative workflow or write boilerplate code from scratch.
This is where dlt enters the picture.
It's an open-source ELT tool that comes as a Python library.
It offers a declarative DSL for defining ingestion pipelines while maintaining the flexibility to use imperative Python code when necessary.
Here's what you can define declaratively:
- Source (pre-built or custom connector) / Destination
- Normalization rules
- Data contract enforcement
In the case of an API, the configuration looks like this:
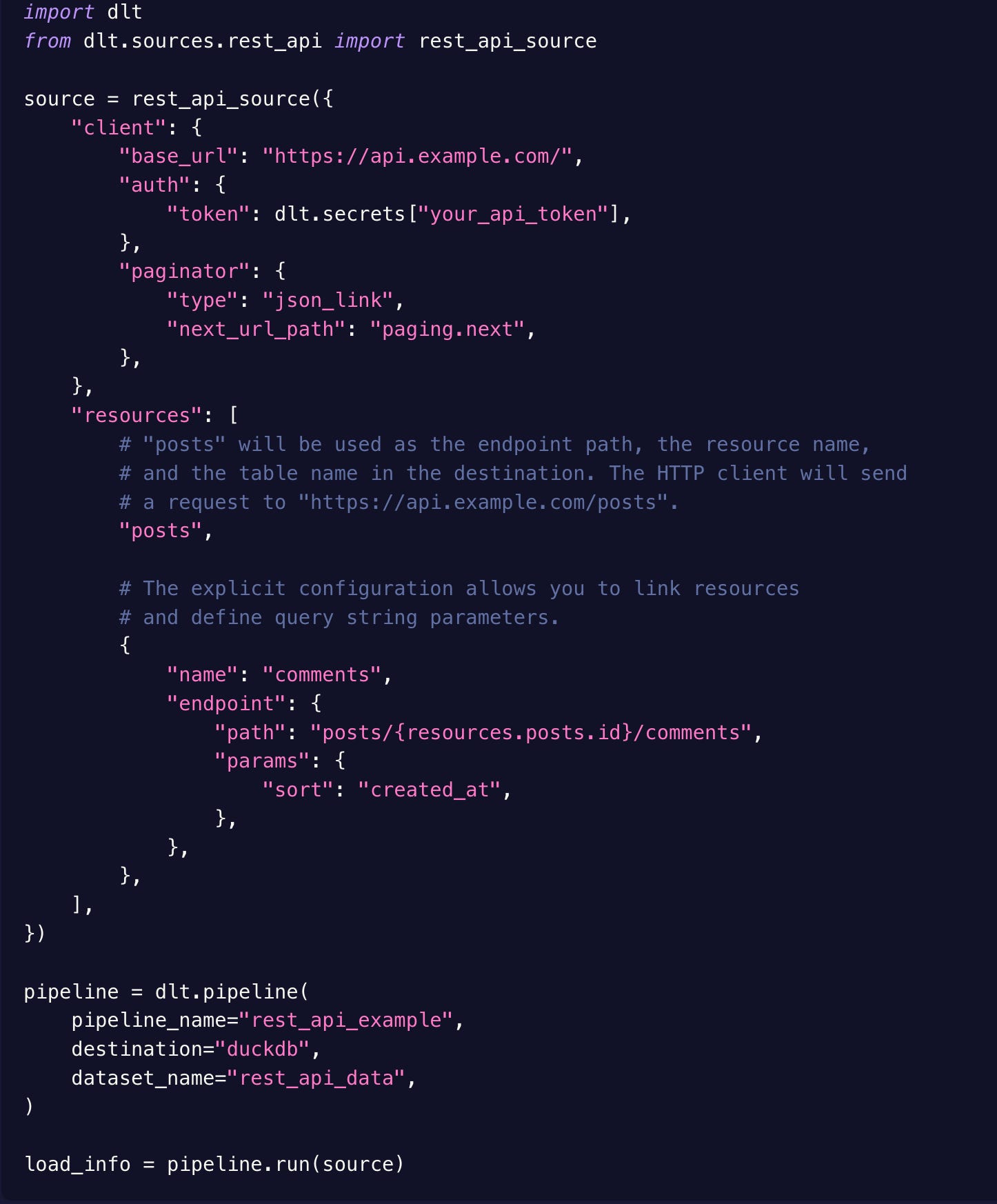
Because it’s native Python, it’s easy to switch to imperative mode when needed—for example, to extend a connector or tweak normalization logic.
And yes, true to this article’s title, generating ingestion pipelines dynamically from a (TOML) config file is possible.
That’s precisely what was done in this example:
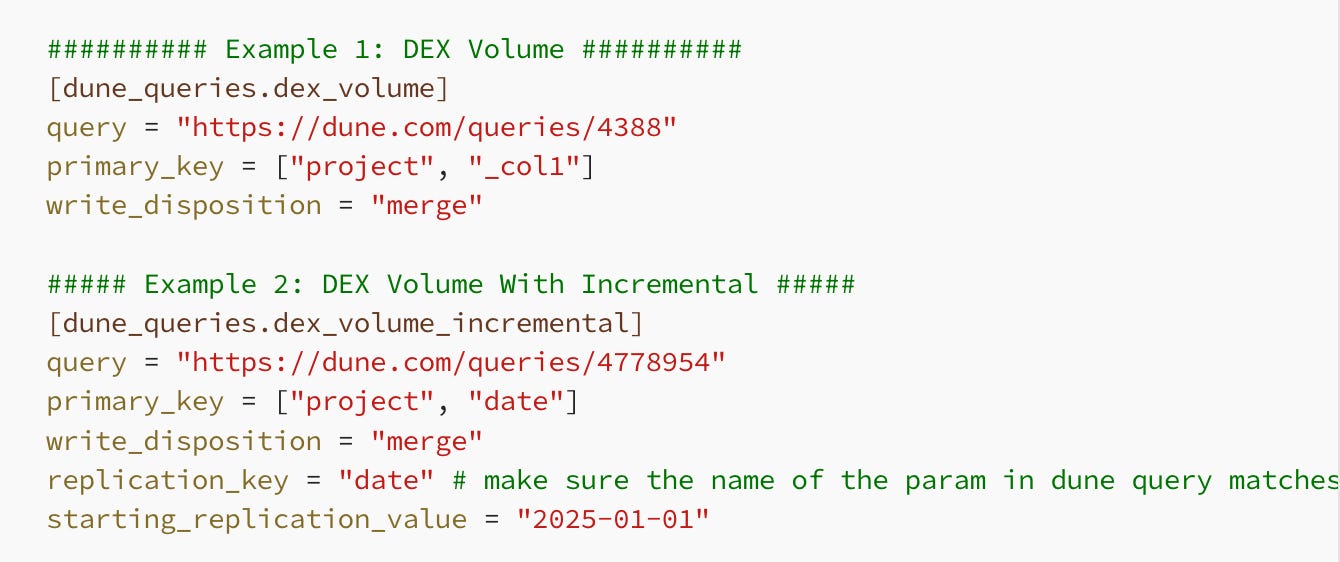
From data engineer to TOML engineer
2- Declarative Data Transformation: SQLMesh
Let’s move further down the data flow: transformation.
But instead of focusing on SQL syntax, I want to look at this from the orchestration angle.
dbt was one of the first frameworks to popularize this declarative approach, especially for defining how models should be materialized.
dbt handles the SQL logic for creating the model and managing incremental updates.
No need to manually write SQL to handle MERGE statements or deduplication—it’s abstracted away.
{{
config(
materialized='incremental',
unique_key='id'
)
}}
SELECT ...
However, dbt has a limitation: it's stateless.
It has, therefore, limited awareness of execution history and timing.
Determining which models need to run is challenging, requiring comparisons of run artifacts.
SQLMesh advances the declarative paradigm by introducing stateful orchestration.
It executes models and maintains a complete execution history, automatically determining what needs to be re-run based on code changes and data freshness.
All this happens without requiring manual DAG configuration in your orchestrator or job scheduler.
You say:
MODEL (
name my.model,
cron '5 4 1,15 * *' -- Run at 04:05 on the 1st and 15th of each month
)
SELECT * FROM ...
And SQLMesh tracks the last run, checks the model frequency, and decides whether to execute.
It bridges the gap between transformation and orchestration—you stay in the declarative world the whole time.
3- Declarative BI: Rill
Let's continue our journey down the data flow—this time arriving in the BI world.
The software engineering mindset seems to stop with traditional BI tools just before BI begins.
Cross that frontier, and you'll be met with endless clicking: there is no version control, reproducible environments, or modular logic.
You're left building dashboards by hand, from scratch, every single time.
I'm excited to see BI finally embrace software engineering principles through BI-as-code tools like Rill, Light Dash, and Evidence.

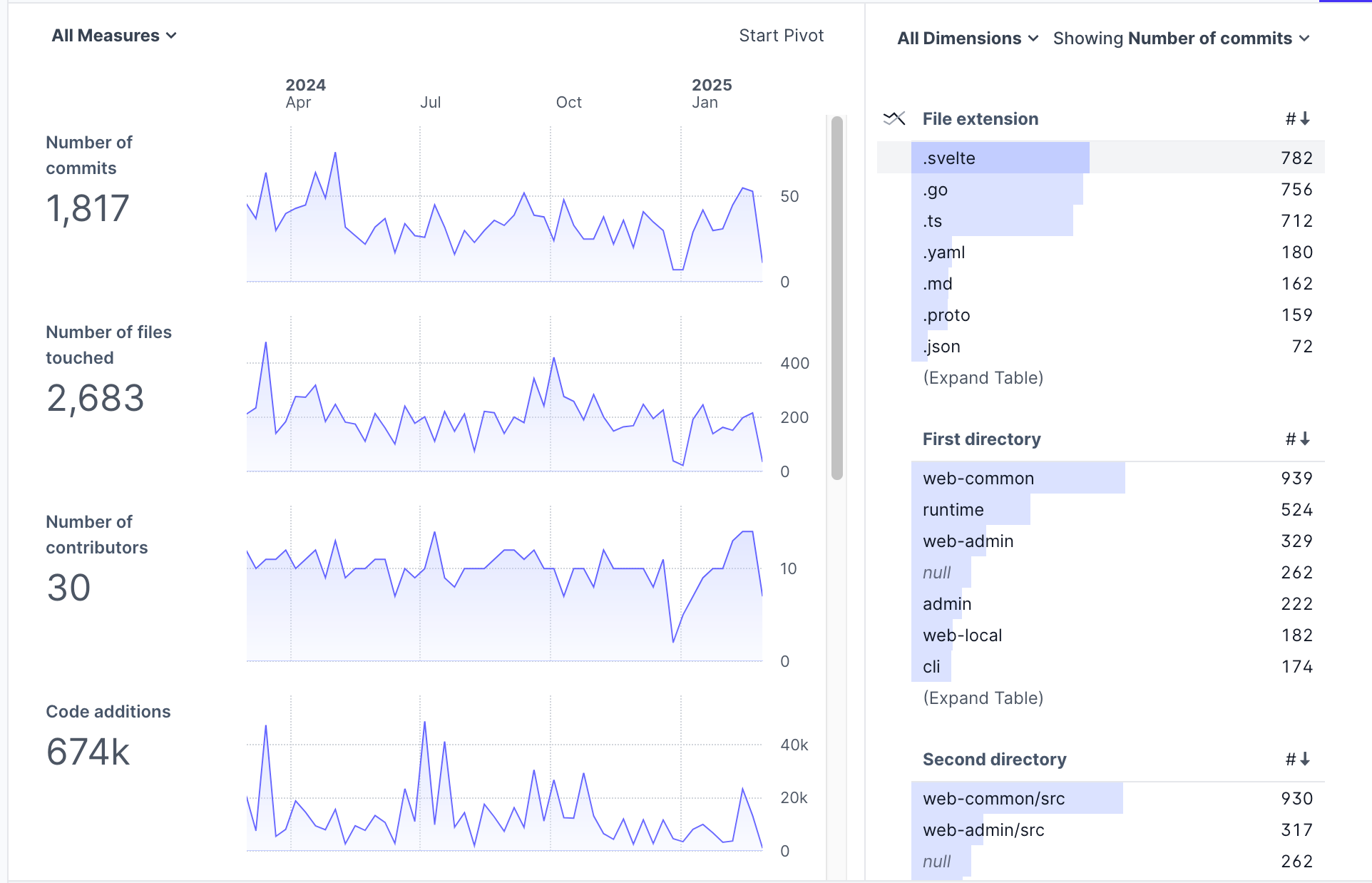
A Rill project, for example, consists of YAML files defining dashboards, metrics, and sources:

You get interactive charts and dashboards that are reproducible, version-controlled, and easy to share across environments.

4- Declarative Data Platform: Starlake
Let’s flip the script and look at Starlake, an open-source tool combining both ingestion and transformation in a unified declarative framework.

Starlake doesn’t rely on external libraries or frameworks.
Instead, they've built their own ingestion engine, transformation framework (with a custom SQL parser), and YAML interface.
This unified approach allows users to define their entire pipeline in a single YAML file:
extract:
connectionRef: "pg-adventure-works-db"
# Additional extraction settings...
---
load:
pattern: "my_pattern"
schedule: "daily"
metadata:
# Metadata configurations...
---
transform:
default:
writeStrategy:
type: "OVERWRITE"
tasks:
- name: most_profitable_products
writeStrategy:
type: "UPSERT_BY_KEY_AND_TIMESTAMP"
timestamp: signup
key: [id]
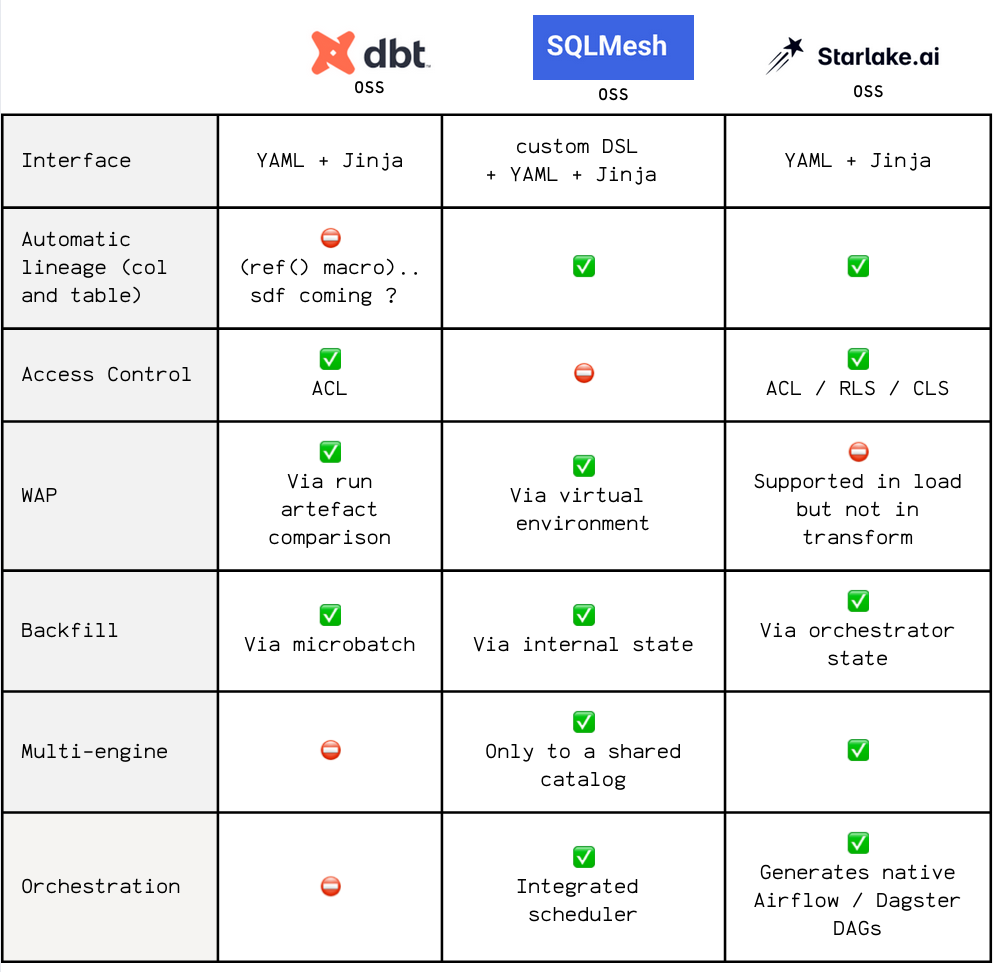
Building both ingestion and transformation frameworks from scratch makes them direct competitors to many actors.
Here's a recap of how they position themselves vs dlt for the ingestion:
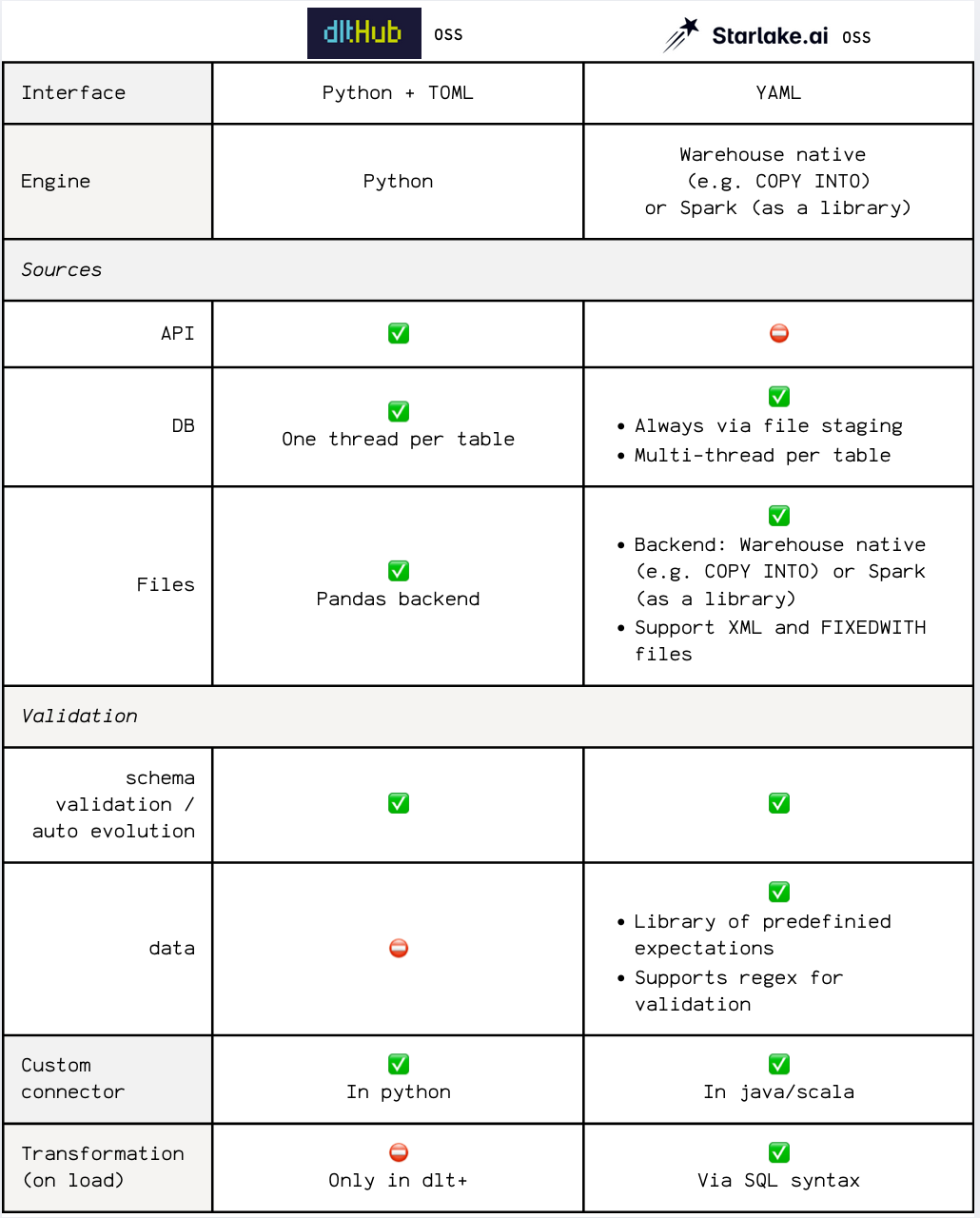
And vs dbt and SQLMesh for the transformation:
Finally, the open source version of Starlake comes with a UI where users can directly edit the YAML config and SQL transformation (with an AI assistant)
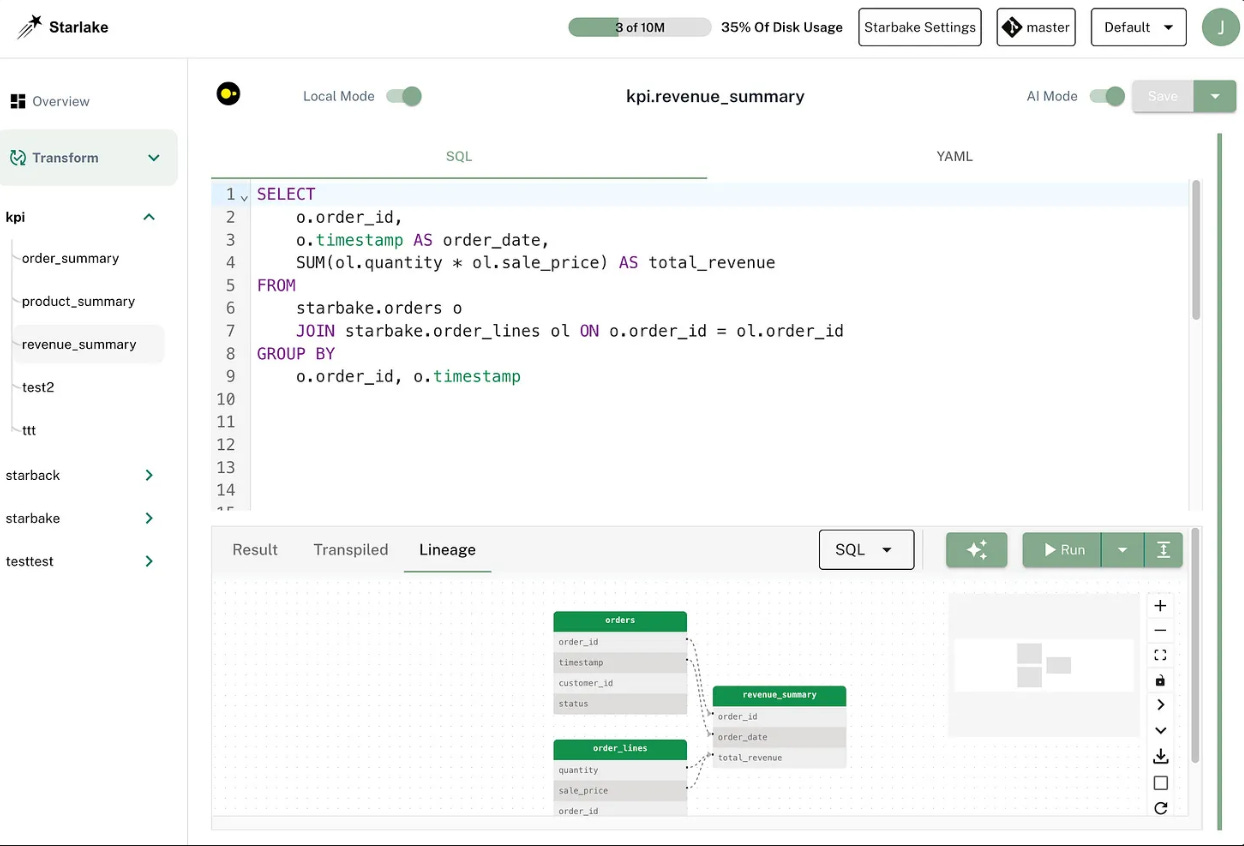
Starlake UI is open source as well
The main advantage of such an approach is that it provides a consistent interface for the whole data lifecycle without the need to learn and manage many different tools.
Check out their GitHub to get started with Starlake or learn more.
Thanks for reading, and thanks, Starlake, for supporting my work and this article.
-Ju

I would be grateful if you could help me to improve this newsletter.
Don’t hesitate to share with me what you liked/disliked and the topic you would like to be tackled.
P.S. You can reply to this email; it will get to me.
Thanks for reading Ju Data Engineering Newsletter! Subscribe for free to receive new posts and support my work.
Subscribe