Introducing Starlake.ai
· 2 min read

We're excited to unveil Starlake.ai, a groundbreaking platform designed to streamline your data workflows and unlock the full potential of your data. 🚀
The Challenges We Solve
In the modern data landscape, businesses often face these challenges:
- Overwhelming complexity in managing data pipelines
- Inefficiencies in transforming and orchestrating data workflows
- Lack of robust governance and data quality assurance
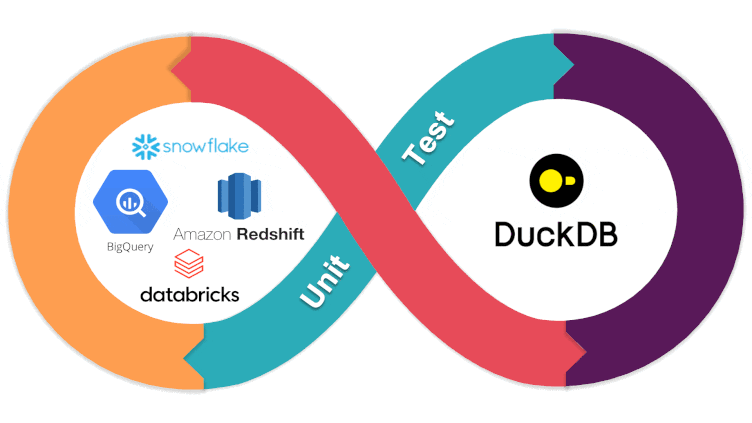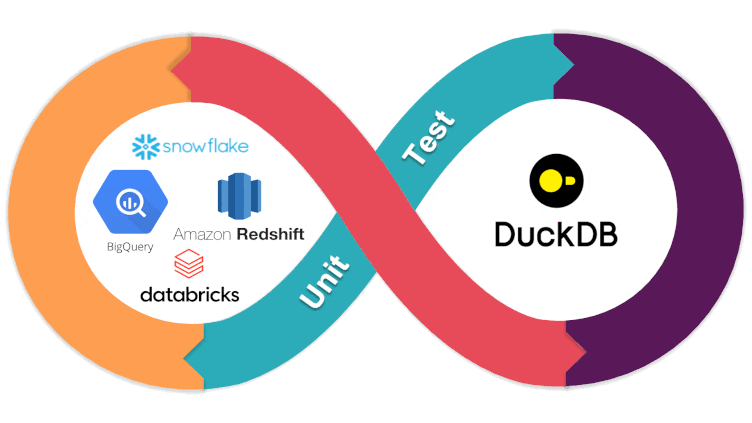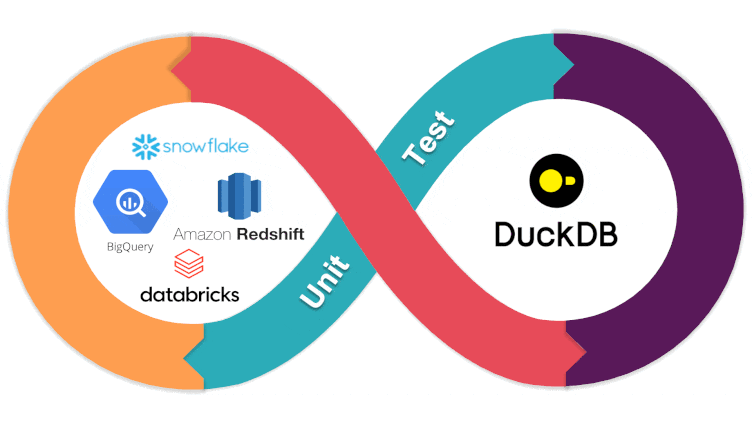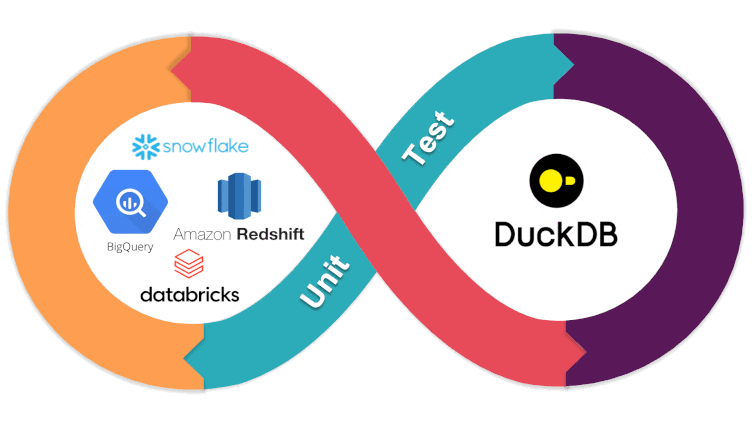
Starlake tackles these problems head-on, offering a declarative data pipeline solution that simplifies the entire data lifecycle.