Incremental models, the easy way.
· 3 min read

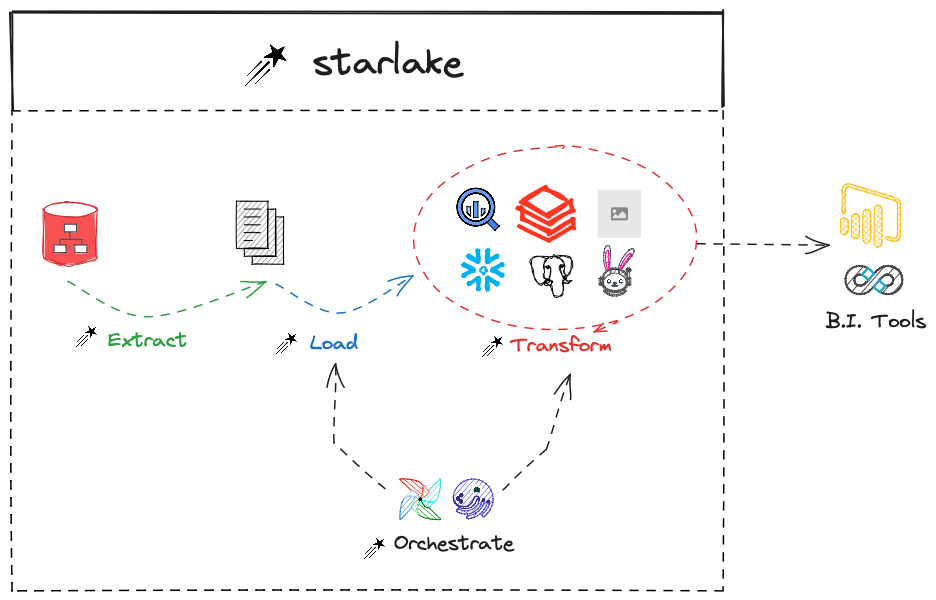
Incremental models, the easy way.
One of the key advantages of Starlake is its ability to handle incremental models without requiring state management. This is a significant benefit of it being an integrated declarative data stack. Not only does it use the same YAML DSL for both loading and transforming activities, but it also leverages the backfill capabilities of your target orchestrator.